As systems move towards microservices, services constantly talk to each other. One service depends on another, which might depend on a third. While this makes systems flexible and scalable, it also introduces a new problem – failures can spread quickly.
A single slow or failing service can impact the entire system. That’s where the Circuit Breaker pattern becomes important.
What is Circuit Breaker Pattern?
At its core, the Circuit Breaker pattern is about stopping repeated failures from causing bigger problems. Instead of continuously calling a service that’s already failing, the system temporarily blocks those requests. This prevents unnecessary load and gives the failing service time to recover.
It helps answer questions like:
What if a service is down? Should we keep retrying? How do we avoid system-wide slowdowns?
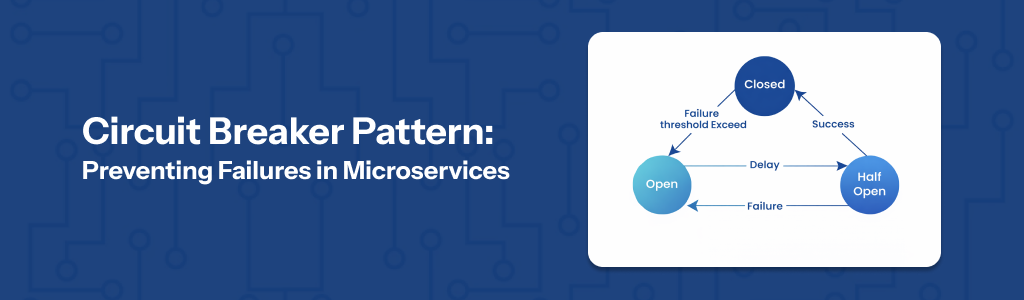
The Three States of Circuit Breaker
1. Closed
This is the normal state. Everything is working fine, and requests flow between services without any interruption.
2. Open
When failures cross a certain threshold, the circuit “opens.” This means requests to the failing service are stopped immediately, avoiding further damage.
3. Half-Open
After some time, the system allows a few test requests. If they succeed, the circuit goes back to normal. If not, it remains open.
Why It Matters in Real Systems
In real-world applications, failures are not rare – they’re expected.
The Circuit Breaker pattern helps teams:
• Prevent cascading failures across services
• Reduce system load during outages
• Improve response time by failing fast
• Provide fallback responses instead of crashing
A Simple Example
Imagine your application depends on a payment service. If that service becomes slow, your system might keep waiting for responses.
With a circuit breaker, instead of waiting, the system immediately stops calling it and shows a message like “Payment service unavailable”. Meanwhile, it keeps checking if the service has recovered.
Final Take
The Circuit Breaker pattern isn’t about avoiding failures – it’s about handling them smartly. In distributed systems, where everything is connected, knowing when to stop is just as important as knowing when to try again.