Big O – A beginner’s guide
- December 26, 2018
- Posted by: Rahul Thachilath
- Categories:
In computer science Big O notations is a way to describe the performance or complexity of an algorithm in terms of Speed and Space it requires to execute.
Formal Definition
f(x)=O(g(x)) means that there exists two positive constants, x1 and c, such that 0≤f(x)≤cg(x) for all x≥x1.
First positive constant:x1
When saying f(x)=O(g(x)), we say “f of x is big-O g of x”.
Here f(x) is a function and O(g(x)) is a set.This doesn’t mean a function is equals to a set. It simply means that the function is a part of set.
I.e. : f(x) belongs in a set of functions called O(g(x))(big-O g of x).
E.g. Consider this function a(x)=5x2+ 10x+100. For x=1 it will be 115 and for x=10 it will be 700.
Second positive constant: c
In the above example we saw how the figure exponentially risen. The main cause of the rise was x2 part. This tell us that f(x)=O(x2). In big O we don’t care about the constants as long as f(x) stays smaller than the scaled version.
I.e. x=1; 0≤a(x2)≤a(5x2). So f(x)=a(x2).
Practical use
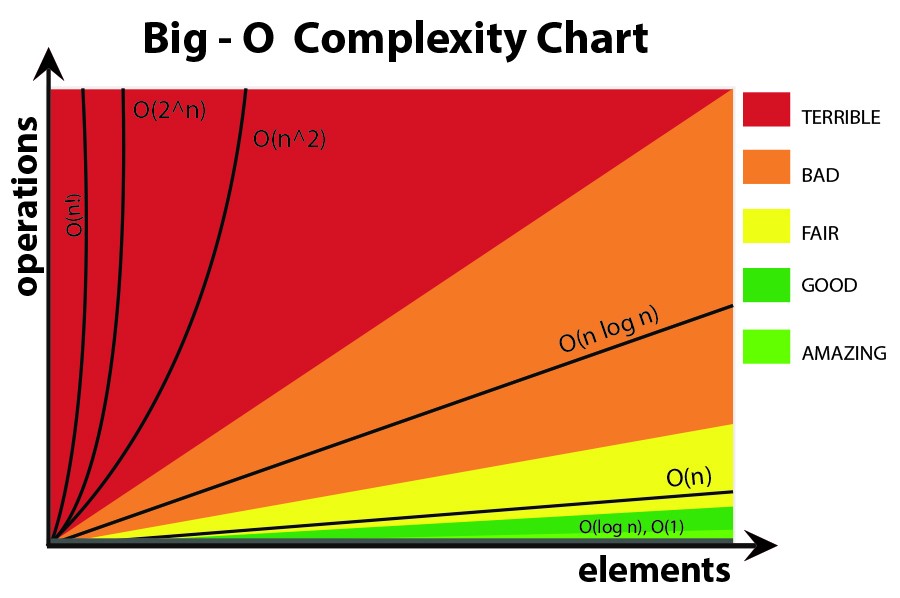
O(1)
O(1) describes an algorithm that will always execute in the same time (or space) regardless of the size of the input data set.
boolean IsFirstElementNull(IList<String> elements) { return elements[0] == null; }
O(N)
O(N) describes an algorithm whose performance will grow linearly and in direct proportion to the size of the input data set. The example below also demonstrates how Big O favours the worst-case performance scenario; a matching string could be found during any iteration of the for loop and the function would return early, but Big O notation will always assume the upper limit where the algorithm will perform the maximum number of iterations.
boolean ContainsValue(IList<String> elements, String value) { foreach (String element in elements) { if (element.equals(value)) return true; } return false; }
O(N2)
O(N2) represents an algorithm whose performance is directly proportional to the square of the size of the input data set. This is common with algorithms that involve nested iterations over the data set. Deeper nested iterations will result in O(N3), O(N4) etc.
boolean ContainsDuplicates(IList<String> elements) { for (String outer = 0; outer < elements.Count; outer++) { for (String inner = 0; inner < elements.Count; inner++) { // Don't compare with self if (outer.equals(inner)) continue; if (elements[outer].equals(elements[inner])) return true; } } return false; }
O(2N)
O(2N) denotes an algorithm whose growth doubles with each additon to the input data set. The growth curve of an O(2N) function is exponential – starting off very shallow, then rising meteorically. An example of an O(2N) function is the recursive calculation of Fibonacci numbers:
int fibonacci(int number) { if (number <= 1) return number; return fibonacci(number - 2) + fibonacci(number - 1); }
Logarithms
Logarithms are slightly trickier to explain so I’ll use a common example:
Binary search is a technique used to search sorted data sets. It works by selecting the middle element of the data set, essentially the median, and compares it against a target value. If the values match it will return success. If the target value is higher than the value of the probe element it will take the upper half of the data set and perform the same operation against it. Likewise, if the target value is lower than the value of the probe element it will perform the operation against the lower half. It will continue to halve the data set with each iteration until the value has been found or until it can no longer split the data set.
This type of algorithm is described as O(log N). The iterative halving of data sets described in the binary search example produces a growth curve that peaks at the beginning and slowly flattens out as the size of the data sets increase e.g. an input data set containing 10 items takes one second to complete, a data set containing 100 items takes two seconds, and a data set containing 1000 items will take three seconds. Doubling the size of the input data set has little effect on its growth as after a single iteration of the algorithm the data set will be halved and therefore on a par with an input data set half the size. This makes algorithms like binary search extremely efficient when dealing with large data sets.